Why GraphRAG Needs a Better Backbone Than Leiden Clustering
If you’ve built a RAG pipeline, you’ve probably hit the ceiling: your system handles factual lookups well, but falls apart when someone asks a question that requires synthesizing an entire corpus. “What strategies have semiconductor companies adopted in response to supply chain disruptions over the past decade?” No single retrieved chunk will answer that. You need the system to reason across hundreds of documents, identify recurring themes, and reconcile conflicting perspectives. This is what people call global sensemaking, and it’s where standard RAG reaches its limits.
GraphRAG, introduced by Edge et al. at Microsoft Research, was a significant step forward for corpus-level question answering. Their key insight was to add a structural layer on top of the corpus. First, an LLM extracts entities and relationships from text chunks, building a knowledge graph. Then, the graph is partitioned into hierarchical communities using Leiden clustering, a popular modularity-based community detection algorithm. Each community gets recursively summarized, and at query time, these summaries are retrieved and aggregated through a map-reduce process to produce a final answer. It’s a clever architecture: instead of retrieving raw passages, you’re retrieving pre-computed summaries of coherent topic clusters.
But there’s a structural problem hiding in the community detection step. Knowledge graphs have very little local connectivity to work with. Average node degrees tend to be in the low single digits, and a majority of nodes often have just a single connection. Leiden works by optimizing modularity, a score that compares edge density within communities to what you’d expect by chance. When most nodes barely participate in the graph, that comparison loses much of its discriminative power. We prove that in this regime, the number of near-optimal partitions grows exponentially with graph size. In plain terms: Leiden is choosing one partition from an astronomically large set of equally good options, guided more by its random seed than by genuine structure. Run it twice, get different communities, get different summaries, get different answers. That’s a reproducibility problem you don’t want in a production pipeline.
Our alternative is k-core decomposition, a classical graph algorithm that organizes a network into nested layers of increasing minimum degree. The idea is simple: repeatedly peel away nodes with the fewest connections. What remains at each step is a progressively denser and more tightly connected subgraph. Every node gets assigned a core number, the largest k for which it belongs to a subgraph where every node has at least k neighbors. This creates a natural hierarchy: the outer layers capture peripheral entities, while the inner cores correspond to the most interconnected, topically central parts of the knowledge graph. The figure below illustrates this on a small example: the left side shows the core layers, and the right side shows the resulting hierarchy tree.
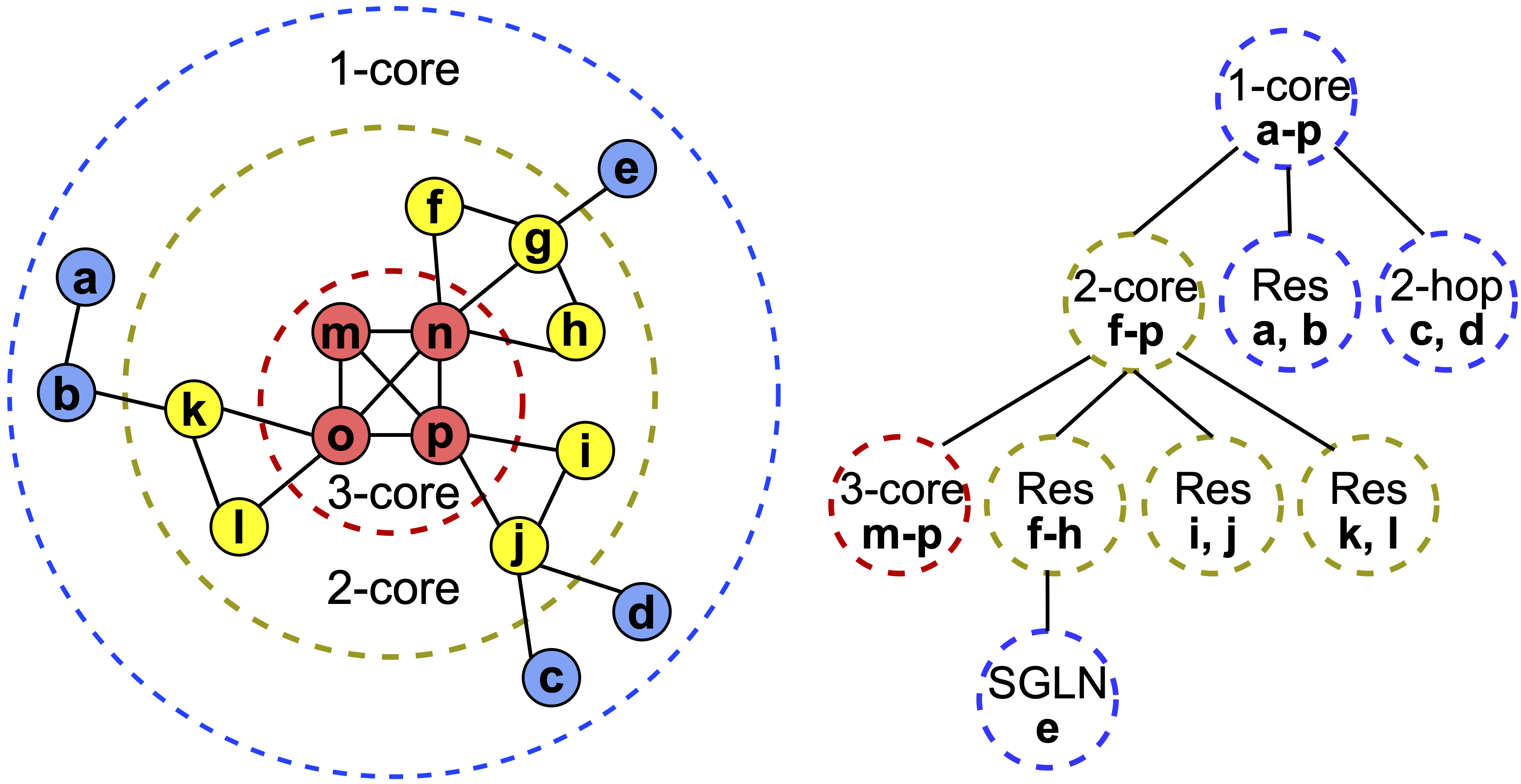
Crucially, k-core decomposition is deterministic. There’s no optimization landscape, no random initialization, no sensitivity to seeds. The same graph always produces the same hierarchy. It also runs in linear time, making it strictly cheaper than Leiden. We build on this hierarchy with a set of lightweight heuristics that construct size-bounded communities suitable for LLM summarization, and handle small or residual clusters that naturally arise from the peeling process. On top of that, we introduce a separate token-budget-aware sampling strategy. In densely connected leaf-level communities, many nodes and edges carry overlapping information, and passing all of it to the LLM is both costly and redundant. Our sampler selects a representative subset of edges from each community in a round-robin fashion, keeping the most informative content while significantly cutting token usage.
We evaluated our k-core heuristics against Leiden-based GraphRAG across three real-world datasets: podcast transcripts, news articles, and semiconductor earnings calls. For answer generation, we used three LLMs (GPT-3.5-turbo, GPT-4o-mini, and GPT-5-mini), and for evaluation we used five independent LLM judges in a head-to-head format, where each judge picks a winner, loser, or tie on every question. This setup was deliberately broad: we wanted to know whether the gains hold across different corpora, models, and evaluators, not just in one favorable configuration.
They do. Across datasets and models, our k-core heuristics consistently improve both answer comprehensiveness (how thoroughly the answer covers all relevant aspects of a question) and diversity (how well it captures varied perspectives and insights). On GPT-3.5-turbo, our best-performing heuristic wins 55 to 65% of head-to-head comparisons depending on the dataset and metric, with statistical significance (p < 0.005) across all three datasets for comprehensiveness. With stronger models like GPT-4o-mini and GPT-5-mini, the margins narrow as you’d expect, since the models’ own knowledge starts compensating, but the directional advantage on both metrics remains consistent.
The efficiency story is equally compelling. Our heuristics naturally produce more compact community structures, using fewer communities and covering fewer total tokens than Leiden at comparable hierarchy levels. On top of that, our round-robin token sampling strategy can reduce token usage by up to 40% relative to Leiden while still maintaining competitive win rates in the 50 to 56% range. For anyone running GraphRAG at scale, that’s a meaningful cost reduction.
There’s also a practical benefit that doesn’t show up in win rates: reproducibility. Because k-core decomposition is deterministic, the same corpus always produces the same communities, the same summaries, and the same retrieval behavior. There’s no variance from random seeds, no need to run the pipeline multiple times to check stability. For production systems, that predictability matters.
If you’re building or maintaining a GraphRAG pipeline, the community detection step deserves more scrutiny than it usually gets. Leiden is a reasonable default for dense networks, but knowledge graphs aren’t dense networks, and the instability that follows has real downstream consequences. k-core decomposition, combined with a set of lightweight heuristics for community construction, sizing, and token budgeting, gives you a deterministic, efficient, and well-understood alternative that produces better summaries with fewer tokens. The code is publicly available and the full paper is on arXiv.