Putting the Convergence Guarantee Back Into Parallel Louvain
If you’ve ever clustered a graph in production, you’ve probably used Louvain. Introduced by Blondel and colleagues in 2008, the Louvain algorithm has become the default tool for finding communities in networks (just noticed that Vincent Blondel became a rector at UCLouvain after this paper, then a senator, and now serves as the current president of the Belgian Senate - wow). Biologists use Louvain to group proteins. Bibliometric platforms use it to organize the scientific literature. Banks use it to find fraud rings. And more recently, it sits inside GraphRAG and similar systems, partitioning knowledge graphs so an LLM can write topic-level summaries instead of stitching together raw passages.
What’s less well known is that the parallel implementations almost everyone uses today, the ones that actually make Louvain practical on graphs with hundreds of millions of edges, have quietly been violating Louvain’s own convergence proof for over a decade.
Louvain itself is a simple, elegant idea. It is an agglomerative (bottom-up) clustering technique where each node starts as its own community. Louvain repeatedly cycles through two phases. In the local-move phase, it walks over every node in the graph and asks: is there a neighboring community I’d be happier joining? If the answer is yes — measured by a quantity called modularity, which compares the density of edges inside communities to what you’d expect by chance — the node moves. After a full sweep of moves, the algorithm collapses each community into a single super-node, builds a coarser graph from the result, and recurses. The original 2008 paper proves something important about this loop: modularity is non-decreasing across moves. Since modularity is bounded above and only finitely many partitions exist, the algorithm has to terminate. That termination guarantee is exactly what stops working the moment you parallelize (even in shared memory).
The reason is subtle but well-understood. When multiple threads each ask “what’s the best move for my node?” at the same time, they’re all reading the current state of the communities. If two threads simultaneously decide to join the same community, each of them sees a positive modularity gain individually — but the joint effect, once both moves land, can actually be negative. Worse, two adjacent nodes can simultaneously decide to migrate into each other’s community, get no net gain, and end up in an infinite ping-pong, swapping back and forth on every iteration. Both failure modes come from the same root cause: each thread acts on stale information about what the other threads are doing.
This isn’t a bug, exactly. It’s a structural consequence of running an inherently sequential computation in parallel. And every popular shared-memory implementation of parallel Louvain — Grappolo, PLMR, the Pull/Push variant — has worked around it the same way: heuristically. They cap the iteration count. They stop early when modularity improvements fall below a threshold. They shrug and accept that the algorithm “usually terminates in practice.”
And this indeed works. But “usually terminates” isn’t the same thing as “guaranteed to terminate.” And as Louvain has crept into regulated industries, audit-sensitive pipelines, and AI infrastructure where correctness, traceability, and stability are essential, that distinction has started to matter. Louvain does not specify in which order the nodes must be processed, and hence there are many valid sequential runs with slightly different results. But parallelism without convergence makes it worse. Guaranteeing that a parallel Louvain run corresponds to some sequential execution brings meaningful operational value.
Our paper, which we’ll present at IPDPS 2026, gives the first parallel Louvain algorithms that come with a real convergence proof — not “converges in practice,” but provably terminates and produces a partition that’s mathematically equivalent to some sequential Louvain run. There are two of them.
The first, distance-2 community coloring, is mostly there to make the theory crisp. The idea is to assign colors to nodes such that two nodes only share a color if they couldn’t possibly interfere — neither they nor their neighbors are members of overlapping communities. See the figure below. Nodes with the same color can then be processed in parallel, because the constraint guarantees their moves touch disjoint pieces of state. The catch is that the coloring depends on the current partition, so it has to be recomputed as communities merge. We do this incrementally. The proof is clean: any execution order on a color class yields the same partition as a sequential run, so the whole computation can be serialized back to standard Louvain. But it’s expensive in practice. Real-world graphs need wide color palettes, and you end up with many small color classes — lots of synchronization barriers, low utilization. This method demonstrates the principle but isn’t the one we’d actually recommend running.
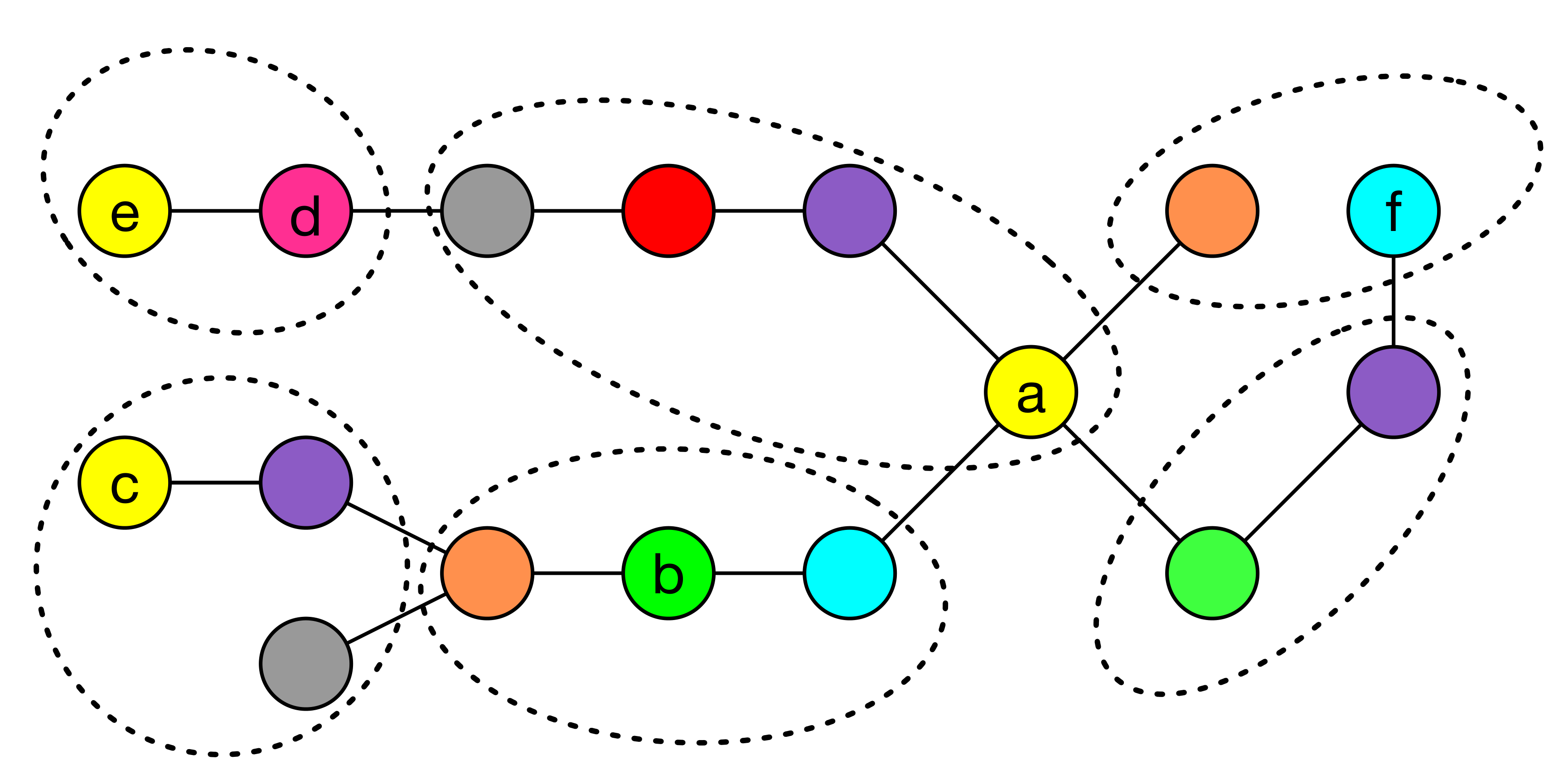
The second method, community versioning, is what we recommend. It borrows a well-known idea from database concurrency control: two-phase locking with version numbers. Each community gets a counter. An even number means the community is stable — safe to read. An odd number means someone is in the middle of modifying it.
When a thread wants to move a node, it does three things. First, it reads the current state, only inspecting communities whose versions are even. Second, it computes the best possible move from that consistent snapshot. Third, it attempts to lock both the source and destination communities atomically, by checking that their versions haven’t changed since it first read them. If they haven’t, the move commits. If they have, which means some other thread modified one of those communities in the meantime, the thread reverts, defers the node to the next iteration, and tries again later.
This sounds fiddly, but it’s exactly the kind of optimistic concurrency control that databases have used for decades to make concurrent transactions safe. The key property is that whenever a thread successfully commits a move, the modularity gain it computed is guaranteed to be valid — no other thread has touched the relevant communities between the read and the commit. From there, you can show that the entire parallel execution is serializable: there exists a sequential ordering of the committed moves that would produce the exact same final partition. And that sequential ordering is itself a valid Louvain run, which inherits the original convergence proof from the 2008 paper.
So how does this perform? We tested on seven real-world graphs ranging up to Orkut at 117 million edges, on a 40-core machine. The headline: our versioning-based method, which we call VLM, matches the speed of PLMR and Grappolo closely across the board — sometimes faster, sometimes slower, but never far off. On each dataset, VLM either produces the highest modularity or sits within a narrow range of the best heuristic baseline. Against sequential Louvain, the only other method that also guarantees convergence, VLM is around 435 times faster on the largest network we tested. And on a synthetic graph with 40 million nodes and 400 million edges, it finishes in under five minutes.
Most importantly, every run produces an outcome that can, in principle, be traced back to a deterministic sequential execution. No heuristic patches. No early-termination thresholds papering over a missing proof. Just an algorithm that does what it claims to do.
If you’re running Louvain — or its close cousin Leiden, which uses the same local-move phase and is even more popular today — at any kind of scale where reproducibility matters, this is the trade-off we think is worth making. You give up at most a small constant factor in wall-clock time. In exchange, you get something the existing parallel methods cannot offer: a guarantee that the algorithm finishes, and that what it finishes with is consistent with the theory it’s supposed to be implementing.
On a personal note, this work felt like nostalgia. Graph coloring is the closest I’ve come to practicing an art. My very first paper was on parallel graph coloring, with my then-PhD advisor Ümit. Fifteen years later, here’s another parallel graph algorithm — coloring again — but this time with my own PhD advisee Jason, his academic grandfather Ümit, and his academic uncle Yusuf. Onward to the next coloring.
Enjoy Reading This Article?
Here are some more articles you might like to read next: